Description:
Princeton Docket # 05-2158
To date, there is no practical similarity search engine for
general-purpose high-dimensional data and there is no index engine for
similarity search. Current search
engines such as the Google search engine perform exact searches on text
documents and text annotations of non-text data.
Researchers at Princeton University have developed a
content-addressable and ¿searchable storage system for managing and exploring
massive amounts of feature-rich data such as images, audio or scientific
data. Rather than using words to
search the Internet for an image or audio file, this novel technology utilize
multimedia files themselves as queries.
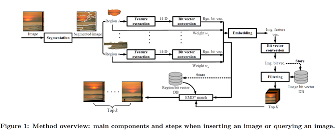
Briefly, data corresponding to an object is first segmented into several
regions. A feature vector is then
generated from each region as well as the whole object, and converted into a bit
vector. This results in very
compact representation of each region, and the distance between two regions can
be calculated. Query data to an
object goes through the same process of segmentation, feature extraction, bit
vector conversion, and embedding. Then the query object bit vector is used to do
filtering in the database and obtain the top objects that are closest to the
query object¿s bit vector. An
illustration of an image similarity search process is shown in Figure 1 below.
Applications
Access, search, explore and manage noisy and high-dimensional data
such as:
·
Audio
·
Video
·
Images
·
Scientific
sensor data
Advantages
·
First
to market potential
·
Demonstrated
high effectiveness
·
Metadata
3 to 72 times more compact than previous systems
·
Query
process speeded up by a factor of 5 or more
Intellectual Property status
U.S. patent application (Patent number: 7966327) has been
issued.